甚麼是演算法(Algorithm)
演算法:為計算機設計的算法(通常很 smart, 但不直覺也不好懂。好的演算法不會犯錯,如果因為設計不完善而犯錯,稱為 bug)
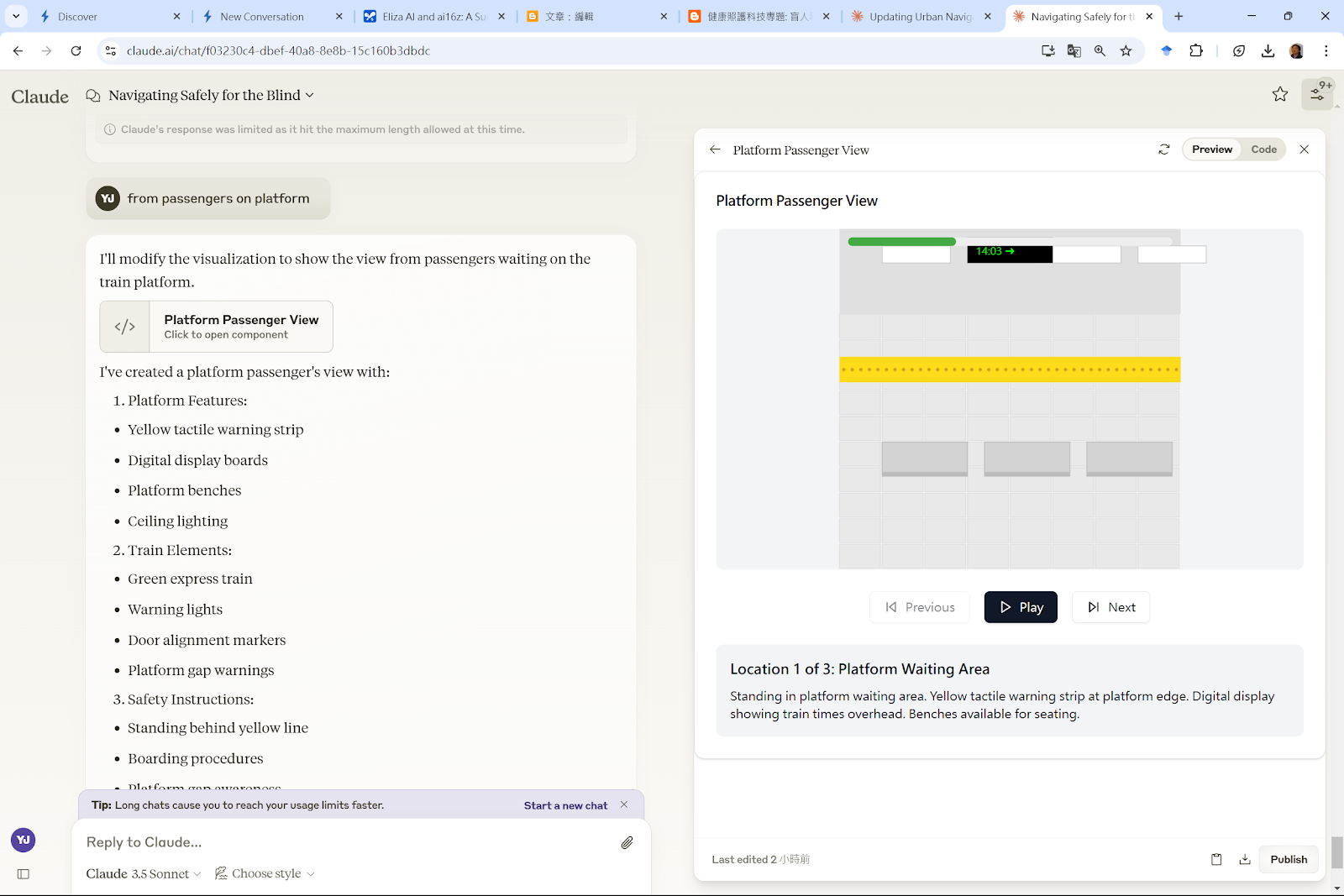
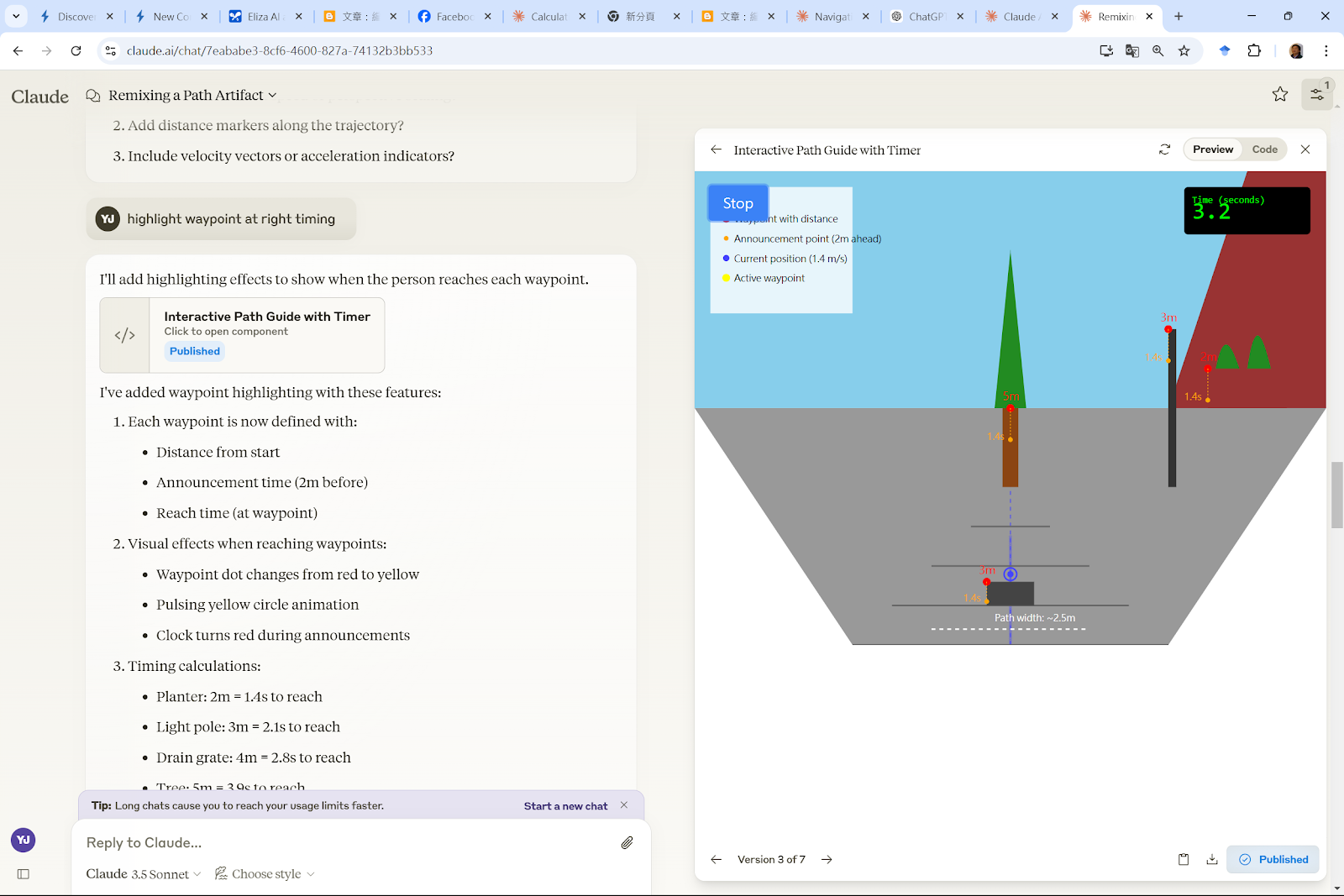
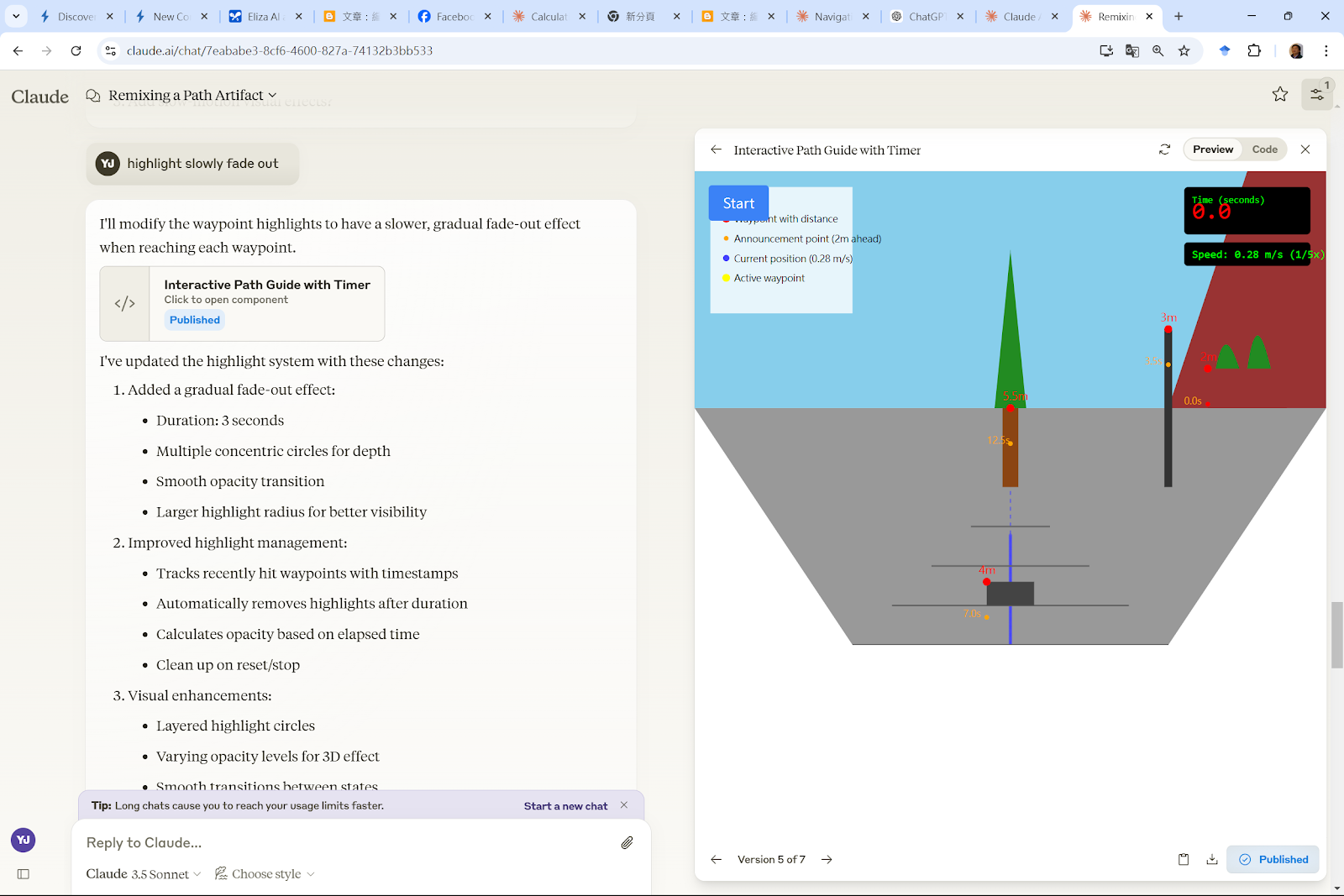
以下介紹著名的電腦演算法,在AI的協助下,即使不懂程式語言,也可以藉由AI 視覺化求解過程來觀察演算法如何解決一些常見的問題,像是找到兩個地點之間的最短距離,推銷員的最佳拜訪路徑等等。
最大公約數 (GCD, Greatest Common Divisor)


Visualize QuickSort (數字排序最常用的演算法之一)



Visualize TSP (Traveling Salesman Problem) by A* search (一個推銷員要拜訪所有客戶城市,每個城市只能拜訪一次,最後要回到出發城市,請為他/她計算最短的拜訪路徑)

Add editing on canvas by click and drop. (在網頁畫布上直接增加刪除城市)
Solving river crossing puzzles